
들어가기 전에
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다. 데이터베이스의 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것에 있다. 일반적으로 정규화란 크고, 제대로 조직되지 않은 테이블들과 관계들을 작고 잘 조직된 테이블과 관계들로 나누는 것을 포함한다. 정규화의 목적은 하나의 테이블에서의 데이터의 삽입, 삭제, 변경이 정의된 관계들로 인하여 데이터베이스의 나머지 부분들로 전파되게 하는 것이다.
출처 : wikipedia
정규화는 데이터베이스의 데이터를 구성하는 프로세스이다. 중복되거나 일치하지 않는 종속성을 제거해서 테이블들의 관계를 재구성하는 과정을 통해 작고 잘 조직된 관계를 생성한다. 그러니까 정규화된 데이터베이스에서는 하나의 정보(Fact)는 딱 한 번만 나타나게 되는 것이다.
일치하지 않는 종속성은 무엇일까? 만약 직원의 급여를 찾으려고 하면 Customer 테이블과 Employees 테이블 중 어떤 테이블을 확인해야 하는지 생각해 보자. 당연히 Employees 테이블에 종속성이 있으므로 해당 테이블에서 확인할 것이다. 이때 Customer 테이블에서 직원의 급여를 확인하는 것을 일치하지 않는 종속성이라고 표현한다.
그렇다면 어떤 문제로 인해 정규화가 필요한 걸까?
이상(Anomaly) 현상
이상 현상이란 정규화를 거치기 전의 데이터베이스에서 발생할 수 있는 현상으로 데이터들이 불필요하게 중복되어서 테이블의 데이터들을 조작하는 데 문제가 발생할 수 있는 것을 말한다.
아래의 테이블을 예로 들어 살펴보자. 해당 직원 테이블에는 겸직이라는 개념이 있어 하나의 직원이 여러 부서에 소속되어 있다.
| employee_id | name | dept_id | address |
| 23 | Hanny | NJ-001 | Seoul |
| 23 | Hanny | NJ-003 | Seoul |
| 24 | Minji | NJ-019 | Incheon |
| 25 | Haerin | NJ-002 | Daejeon |
| 25 | Haerin | NJ-017 | Daejeon |
| 26 | Daniel | NJ-005 | Busan |
| 27 | Hyein | NJ-023 | Jeonju |
1. 삽입 이상(Insertion Anomaly)
데이터가 삽입될 때 테이블의 불일치가 발생할 경우 발생한다. 만약 어떤 부서에도 해당하지 않은 직원이 새로 들어온다면 어떻게 될까? 직원 테이블에 이 직원을 추가하고 싶어도 부서의 정보가 없기 때문에 테이블에 삽입할 수 없게 된다.
2. 삭제 이상(Delete Anomaly)
데이터를 삭제할 때 의도와 다른 값들도 연쇄적으로 삭제된다. Daniel이 소속되어있는 부서 NJ-005를 삭제한다고 가정했을 때, 그 부서의 정보를 가지고 있는 Daniel의 데이터 정보도 삭제되게 되는 것이다.
3. 갱신 이상(Update Anomaly)
데이터를 갱신할 때 일부 행들만 갱신되어서 모순이 발생한다. Hanny의 주소를 Incheon으로 변경한다고 가정했을 때, 첫 번째 데이터는 Incheon으로 잘 갱신되었으나 두 번째 행은 그대로 Seoul일 경우에 발생한다.
그래서 이렇게 발생하는 현상들을 제거하기 위해 테이블들을 정규화하는 방법을 선택할 수 있다. 아래는 위의 테이블을 정규화해서 두 개의 테이블로 재정의한 테이블들이다.
| employee_id | name | address |
| 23 | Hanny | Seoul |
| 23 | Hanny | Seoul |
| 24 | Minji | Incheon |
| 25 | Haerin | Daejeon |
| 25 | Haerin | Daejeon |
| 26 | Daniel | Busan |
| 27 | Hyein | Jeonju |
| dept_id | name |
| NJ-001 | 23 |
| NJ-003 | 23 |
| NJ-019 | 24 |
| NJ-002 | 25 |
| NJ-012 | 25 |
| NJ-005 | 26 |
| NJ-023 | 27 |
정규화의 유형
데이터베이스 정규화에서 사용하는 정규형들은 여러 가지가 있는데 차례대로 살펴보자.
1. 제1정규형(1NF; First Normal Form)
- 각 테이블에서 중복을 제거한다.
- 관련 데이터 집합에 대해 별도의 테이블을 만든다.
- 기본 키를 사용해서 데이터 집합을 식별한다.
중복되는 항목에 대해 자세히 살펴보기 위해 Customer 테이블의 정보를 보자. 만약 데이터에 저장하려는 고객의 전화번호를 여러 개라면 어떻게 저장할 수 있을까? 아래와 같이 한 컬럼에 여러 개를 넣어서 저장한다면 한 행의 데이터에 정확하게 한 개의 값만이 허용되는 1NF의 규칙에 위배된다.
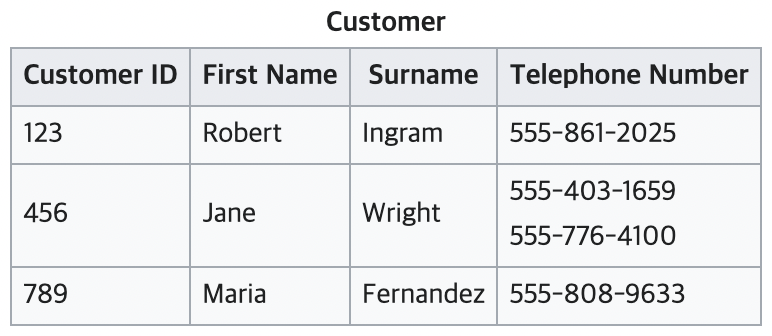
아예 컬럼을 여러 개 만들어서 하나씩 전화번호를 저장하며 되지 않을까? 이렇게 전화번호를 저장한다면 null값이 저장되는 데이터들이 발생하기 때문에 1NF 정의에 위배된다. 그게 아니더라도 Tel. No.1과 Tel. No. 2, Teml. No.3는 동일한 도메인과 의미를 가지기 때문에 좋지 않은 방법이다.

하나의 컬럼으로 가져가되 구분자를 통해 저장하는 방법은 어떨까? 조회 조건에 이 전화번호를 사용한다고 했을 때 명확한 의미로 사용하기가 쉽지 않아진다. 'WHERE Telephone Numbers = '%555-776-4100%'과 같이 검색되어야 하기 때문이다.
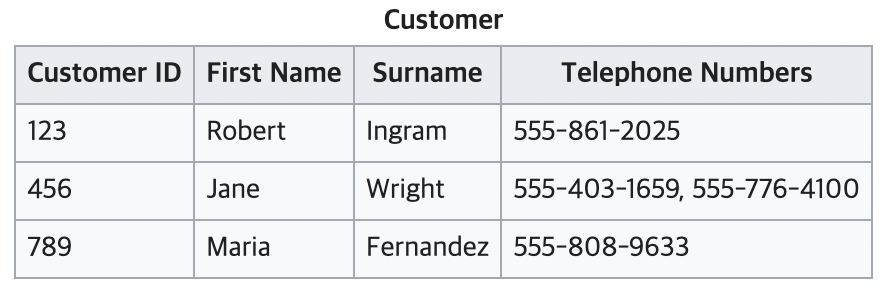
그렇다면 이제는 1NF의 정의에 맞게 테이블을 재설계해보자.

전화번호들의 중복되는 항목이 나오지 않게 일대다 관계의 두 개의 테이블을 생성했다. 하나의 고객 ID에 여러 개의 전화번호를 가지게 되어도 이제는 문제가 발생하지 않는다.
2. 제2정규형(2NF)
- 여러 레코드에 적용되는 값 집합에 대해 별도의 테이블을 만든다.
- 외래 키를 사용해서 테이블 간의 관계를 설정한다.
아래의 테이블에서 후보키는 무엇일까? 종업원의 정보와 기술 모두 유일하지 않기 때문에 이럴 때는 종업원과 기술로 복합키를 만들어야 한다.
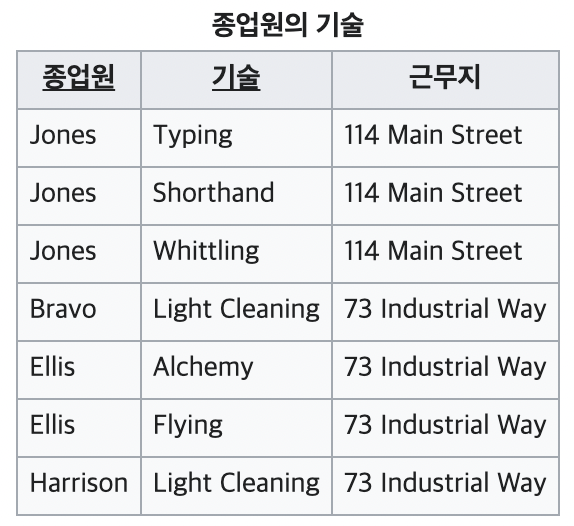
그런데 근무지는 종업원에만 종속성을 가지는 정보이다(부분적 함수 종속). 더군다나 근무지 정보가 중복되어 저장되어있기 때문에 갱신이상의 원인이 될 수 있다. 이럴 때 2NF로 어떻게 테이블을 표현할 수 있을까?
같은 데이터를 아래와 같이 2개의 테이블로 표현했다.

3. 제3정규형(3NF)
- 키에 종속되지 않는 필드를 제거한다.
아래의 테이블의 문제점은 무엇일까? 우승자와 우승자 생년월일이 중복되어있으므로 갱신이상이 발생할 수 있다. 그리고 우승자는 대회, 연도에 의해 결정되고 우승자 생년월일은 우승자에 의해 결정된다.
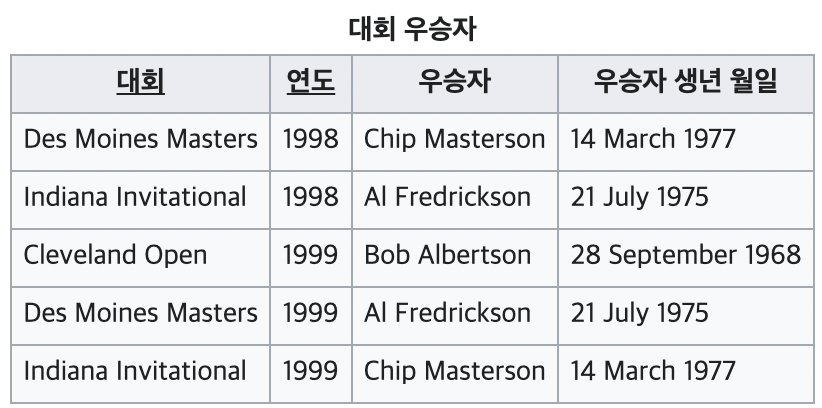
그러니까 A. {대회, 연도}에 의해 B. 우승자가 결정되고, C.우승자 생년월일은 B. 우승자에 의해 결정되는 A -> B -> C 관계인 것이다. 이런 관계를 계속 유지한다면 어떤 연도에 열린 대회의 우승자를 찾는 데 계속해서 불필요한 우승자의 생년월일 정보까지 가지고 있게 된다.
3NF를 만족하는 테이블로 재정의해보자.

4. BCNF(Boyce and Codd Normal Form)
- "X는 Y이다"가 성립할 때 모든 X가 후보키이면 BCNF 정규형이 된다.
아래의 테이블을 보면 {학번, 과목}은 교수를 결정 짓고 교수 또한 과목을 결정짓는다. 하지만 교수는 학번을 결정지을 수 없기 때문에 후보키가 될 수 없다.

이때는 아래와 같이 학생 정보 테이블에서 학번과 과목코드만을 가지고 있게 하고, 과목 정보 테이블에서 과목과 교수를 확인할 수 있게 테이블을 재정의해야 한다.

5. 제4정규형(4NF)
- 다치 종속을 제거해야 한다.
만약에 학생 한 명이 여러 개의 수강 과목을 가지고 있는 테이블이 있다면 이 두 컬럼의 종속 관계를 다치 종속(->>)이라고 표현한다. 이 두 컬럼만 테이블에 있을 때는 문제가 되지 않는다. 문제가 되는 것은 다음과 같이 여러 컬럼의 다치 종속이 있는 경우이다.
| student_id | student_name | subject_name |
| 20230001 | Minji | OS |
| 20230002 | Hanny | OS |
| 20230002 | Hanny | DB |
| 20230003 | Daniel | Network |
이럴 때는 다치 종속 관계가 한 번만 발생할 수 있도록 두 개의 테이블로 나눌 수 있다.
| student_id | student_name |
| 20230001 | Minji |
| 20230002 | Hanny |
| 20230003 | Daniel |
| student_id | subject_name |
| 20230001 | OS |
| 20230002 | OS |
| 20230002 | DB |
| 20230003 | Network |
6. 제5정규형(5NF)
무손실 분해 원칙이 위배되지 않도록 조인 종속성을 이용한다. 무손실 분해란 분해된 두 테이블을 조인했을 때 원래의 테이블의 정보를 완전하게 얻을 수 있는 것을 말한다.
정규화를 사용하는 이유
지금까지 정규화를 통해 해결할 수 있는 이상 현상들과 정규화에는 어떤 유형들이 있는지 알아봤다. 그렇다면 이렇게 정규화를 했을 때 이상 현상을 해결하는 것 말고도 어떤 장점이 있을까? MySQL 성능 최적화에서는 다음과 같은 이유를 말한다.
정규화를 하라는 조언은 대체로 좋은 조언이라고 할 수 있으며, 정규화가 효과적인 이유는 다음과 같다.
1. 대개 정규화된 업데이트는 비정규화된 업데이트보다 빠르다.
2. 데이터가 잘 정규화되면 데이터의 중복이 적거나 없으므로 변경해야 할 데이터도 적어진다.
3. 정규화된 테이블이 더 작으므로 메모리에 잘 들어맞으며 성능이 좋아진다.
4. 데이터의 중복이 없다는 것은 값들을 얻어올 때 쿼리에 DISTINCT나 GROUP BY를 사용할 일이 적어진다는 것이다.
그렇다면 무조건 정규화를 해야만 하는 걸까? 정규화로 인해 재정의된 테이블들의 정보를 조회하기 위해서는 조인을 사용해야 하는데 이때 조인을 위해 임시 저장소를 사용해야 하기 때문에 비용이 더 발생할 수 있고, 혹시 복합 인덱스로 사용하면 좋을 컬럼들도 나뉘어지게 되는 문제가 발생할 수 있다.
비정규화와 역정규화
역정규화(denormailization)는 성능을 개선하기 위해 정규화된 데이터베이스를 되돌리는 것을 의미한다. 정규화를 하지 않을 때를 나타내는 용어는 여러 개가 있는데 위키백과에서는 두 용어를 분리해서 사용하고 있다.
역정규화는 비정규화(unnormalized form)와는 구별한다. 데이터베이스/테이블은 이들을 효율적으로 역정규화하기 위해 우선 정규화되어야 한다.
위키백과의 내용을 어느 정도 신뢰할 수 있을지는 모르겠으나 인터넷 상에 올라온 관련 글들은 이 용어들을 구분해서 사용하지 않는 것으로 보인다. 하지만 非(아닐 비)와 反(돌이킬 반)을 생각했을 때는 위키백과의 내용대로 구분해서 사용하는 것이 맞을 것 같다. 처음부터 정규화하지 않은 것은 비(非)정규화, 그리고 정규화를 했다가 다시 되돌리는 것을 역정규화 또는 반(反)정규화로 말이다. 이 포스팅에서는 MySQL 성능 최적화의 내용을 인용하는 문장들이 많아질 것이기 때문에 비정규화라는 용어로 통일해서 작성하도록 하겠다.
비정규화된 데이터베이스를 사용하는 것에는 어떤 이점이 있을까? 테이블 하나에 모든 정보가 다 들어가니까 정규화를 사용했을 때의 문제점인 조인을 사용하지 않을 수 있다. 조인은 실행 계획 변동이 일어나기 가장 쉬운 연산이므로 성능 문제에 있어서 사용하기 전에 한 번쯤은 고민해야 할 존재이기 때문에 더 의미가 있을 것이다.
그리고 테이블이 하나라면 효율적인 인덱스 전략을 가져갈 수 있다. 단일 인덱스를 사용해서 정렬을 할 수 있는 데이터인데 정규화를 했다면 이 이점을 사용하지 못하기 때문이다.
예를 들어 message 테이블과 user 테이블이 있다고 가정해보자. 사용자 타입이 premium이고 최근 작성한 게시글을 조회한다면 쿼리문은 다음과 같을 것이다. 참고로 published 컬럼은 인덱스로 생성되어있다.
SELECT message_text, user_name
FROM message
INNER JOIN user ON message.user_id = user.id
WEHRE user.accout_type = 'premium'
ORDER BY message.published DESC LIMIT 10;위의 쿼리의 문제점은 무엇일까? 인덱스를 활용할 수 있으면 좋겠지만 찾아낸 행마다 사용자 테이블로 들어가 사용자가 프리미엄 사용자인지 확인해야 하기 때문에 효율적이지 않다. 조인으로 인해서 인덱스를 사용해서 정렬과 필터링을 동시에 할 수 없기 때문이다.
이럴 때는 비정규화를 선택해서 하나의 테이블로 가져가되 account_type과 published를 복합 인덱스로 사용하면 성능상으로 더 좋은 조회를 할 수 있다.
SELECT message_text, user_name
FROM user_messages
WHERE account_type = 'premium'
ORDER BY published DESC
LIMIT 10;
마지막으로 정규화와 비정규화는 이분법적으로 사용되지 않는 경우도 있다. 완전히 비정규화하지는 않지만 그렇다고 정규화는 하지 않는 중간 어디쯤을 선택할 수도 있는 것이다. 예를 들면 분리될 컬럼을 두 테이블에 모두 넣어 이상 현상들을 해결하는 방법도 있다. 만약 위의 쿼리에서 account_type을 message 테이블에도, user 테이블에도 가지게 있게 한다면 삽입 이상과 삭제 이상을 피할 수 있을 것이다. 하지만 양쪽 테이블을 변경해야 하는 경우가 생기므로 변화가 자주 발생하는지를 고려해야 한다.
그래서 정규화와 비정규화를 선택할 때는 각각의 트레이드오프를 잘 고려해야 한다.
면접 예상 질문
- 정규화란 무엇이고 비정규화, 반정규화(=역정규화)란 무엇인가요?
- 정규화를 하는 이유는 무엇인가요?
- 정규화를 했을 때의 이점에는 무엇이 있나요?
- 정규화는 무조건 좋은 것인가요? 아니라면 그 이유는 무엇인가요?
- 비정규화를 하는 이유는 무엇인가요?
- 비정규화를 적용할 수 있는 예를 설명해 주세요.
참고
- SQL 레벨업
- MySQL 성능 최적화
- [위키백과] 데이터베이스 정규화
- [IT위키] 데이터베이스 정규화
- [Microsoft] 데이터베이스 정규화 기본 사항 설명
- Anomalies in DBMS
- [시나공 정보처리] 1404500 정규화
- 정보처리 실기_데이터베이스06강_정규화
'DB' 카테고리의 다른 글
| [DB] 인덱스(2) - B-tree와 B+tree에 대하여 (0) | 2023.03.13 |
|---|---|
| [DB] 인덱스(1) - 인덱스는 왜 사용하는가? (0) | 2023.03.13 |
| [DB] Lock (0) | 2023.03.08 |
| [DB] 트랜잭션(2) - Isolation Level (0) | 2023.03.07 |
| [DB] 트랜잭션(1) - 트랜잭션이란 무엇인가 (0) | 2023.03.07 |



