
들어가기 전에

사용자 A가 SNS을 둘러보다 흥미로운 광고를 발견한다. "잠깐 볼까?" 하며 클릭했지만, 광고 페이지가 로딩에만 10초가 넘게 걸린다면 어떨까? 대부분의 사용자는 기다려주지 않고 페이지를 닫고 다시 SNS로 돌아갈 것이다. 단 몇 초의 지연이 사용자의 이탈로 이어지는 이유는 바로 성능 때문이다.
그렇다면 광고주는 왜 홍보 효과를 얻지 못했을까? 그 이면에는 네트워크 성능을 좌우하는 두 가지 핵심 지표가 있다. 처리량(Throughput)과 지연 시간(Latency)이다.
처리량(Throughput)
처리량은 단위 시간 동안 네트워크가 실제로 처리하는 작업량을 의미한다. 보통 TPS 또는 RPS로 표현된다.
- TPS(Transaction Per Second): 초당 트랜잭션 수
- RPS(Request Per Second): 초당 요청 수
TPS와 RPS는 혼용되서 사용되지만, 의미상 차이가 있으므로 상황에 맞게 구분해 사용하는 것이 좋다.
지연 시간(Latency)과 응답 시간(Response Time)
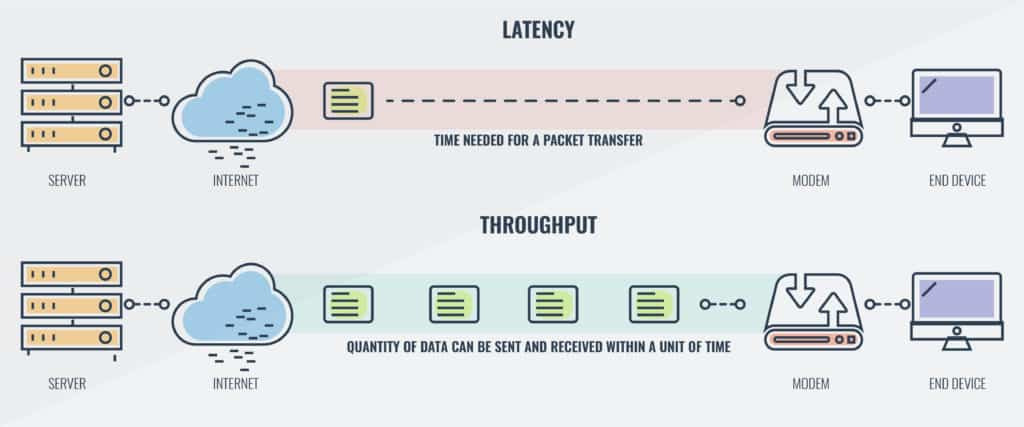
지연 시간은 네트워크 통신 과정에서 패킷이 한 지점에서 다른 지점으로 도달하는 데 걸리는 시간이다. 요청이 왕복하는 데 걸리는 시간, 즉 왕복 시간(RTT, Round-Trip Time)도 중요하게 측정된다.
응답 시간은 사용자가 요청을 보낸 시점부터 최종 응답을 받기까지 걸리는 전체 시간이다.
지연 시간과 응답 시간을 종종 같은 뜻으로 사용하지만 동일하지는 않다. 응답 시간은 클라이언트 관점에서 본 시간으로, 요청을 처리하는 실제 시간(서비스 시간) 외에도 네트워크 지연과 큐 지연도 포함한다.
- 대규모 애플리케이션 설계 p.14
예를 들어, 사용자가 웹에서 상품 검색을 요청했다고 해보자.
| 구간 | 시간 (예시) |
| 사용자의 요청이 서버로 가는 시간 | 50ms |
| 서버가 요청을 처리하는 시간 | 100ms |
| 서버의 응답이 사용자에게 도달하는 시간 | 50ms |
이중 지연 시간은 왕복 기준 100ms, 응답 시간은 총 200ms이 될 것이다.
TPS를 높이는 방법
실제 서비스 사례
2012년 11월에 공개된 트위터의 데이터를 보면, 다음과 같은 수준의 요청이 발생했다.
- 트윗 작성 : 평균 초당 4.6k 요청, 피크일 때 12k 요청 이상
- 홈 타임라인 : 초당 300k 요청
이처럼 높은 TPS에 대응하기 위해 트위터는 데이터 파이프라인 구조를 변경했다. 이때 중요한 개념이 바로 최대 TPS인데, 이는 시스템이 최대로 처리할 수 있는 요청 수를 의미한다. 정해진 처리량을 초과하면 서버는 초과한 요청을 대기열에 쌓게 되면서 응답 지연이 발생한다.
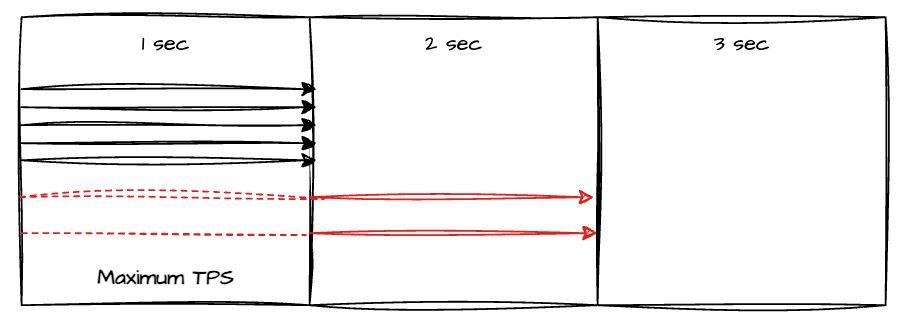
TPS를 높이는 방법
응답 시간을 줄이면 TPS를 높일 수 있다. 이를 위해 적용할 수 있는 대표적인 두 가지 접근법은 다음과 같다.
- 동시에 처리할 수 있는 요청 수 늘리기 (e.g. 서버의 스레드 수 조정, 비동기 처리)
- 한 개의 요청을 처리하는 시간을 단축하기 (e.g. DB 최적화, 캐싱, 불필요한 연산 제거)
어떤 방법을 선택할지는 성능 병목이 어디서 발생하는지에 따라 달라진다. 따라서 가장 먼저 해야 할 일은 현재 서버의 TPS와 응답 시간을 정확히 파악하는 것이다. 특히 트래픽이 많은 시간대의 TPS와 응답시간을 바탕으로 현재 상태를 진단하고, 목표 TPS와 응답 시간을 설정한 뒤 개선안을 도출해야지만 근거 있는 최적화가 가능해진다.
TPS를 확인하는 방법
TPS를 확인하는 가장 간단한 방법은 모니터링 시스템을 활용하는 것이다. 대표적인 APM(Application Performance Monitoring) 도구로는 다음과 같은 것들이 있다.
- Scouter
- Pinpoint
- New Relic
이 도구들은 실시간 TPS뿐 아니라 과거 특정 시점의 TPS도 확인할 수 있어 성능 이슈를 분석하기에 적합하다. 하지만 만약 이런 도구가 없다면, 웹 서버 접근 로그를 파싱해서 TPS를 계산할 수도 있다. 예를 들어, 로그에서 특정 시간 동안 처리된 요청 수를 구한 뒤 초 단위로 나눠 TPS를 추산하는 방식이다.
액션 아이템
이제 실제로 맡고 있는 프로젝트의 TPS와 응답 시간을 알아보려고 한다.
1️⃣ A 프로젝트
다양한 앱에서 들어오는 요청을 감지하고 처리해주는 통합 시스템이다. 현재 CloudWatch를 로깅 및 모니터링 도구로 활용하고 있으며, 별도의 APM 도구는 사용하지 않고 있다. 앞서 언급한 것처럼, APM 도구가 없더라도 CloudWatch와 같은 로깅 적재 도구를 통해 충분히 TPS를 분석할 수 있다.
CloudWatch Log Insights로 TPS 측정하기
AWS CloudWatch의 Log Insights 기능을 활용하면 로그 기반으로 TPS를 측정할 수 있다.
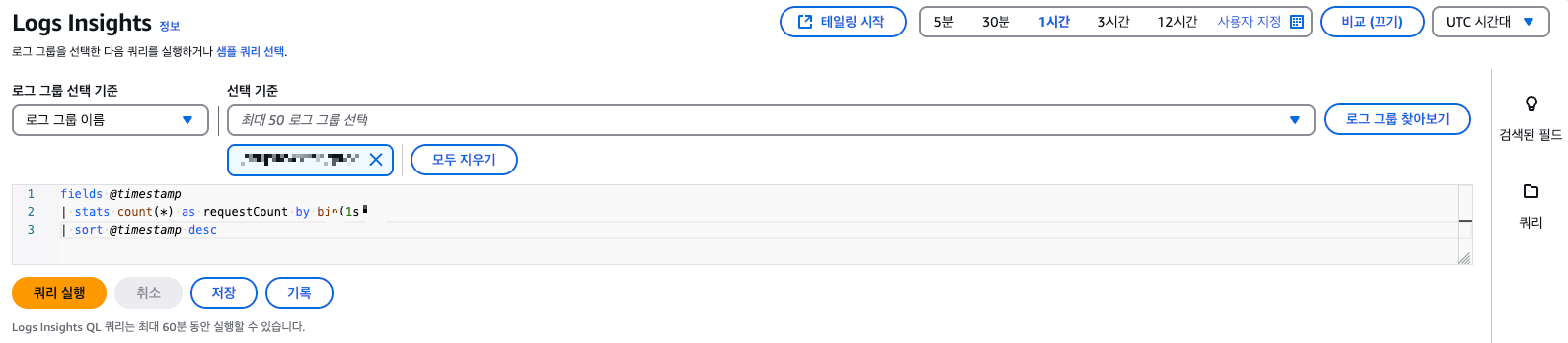
이 쿼리는 로그의 @timestamp 필드를 기준으로 1초 단위로 요청 수를 집계한다. 결과적으로 특정 시간대의 TPS 추이를 파악할 수 있고, 이상 징후나 트래픽 급증 구간을 확인하는 데 유용하다.
fields @timestamp
| stats count(*) as requestCount by bin(1s)
| sort @timestamp desc
CloudWatch에서는 쿼리 결과를 바로 시각화할 수 있다. 시간 구간별 TPS를 그래프로 확인하면 특이점이 훨씬 쉽게 식별이 가능하다.

A 프로젝트의 TPS는 현재 트래픽 기준으로는 안정적인 수준이다. 하지만 연동하는 앱이 늘어나고, 요청 수가 증가하면 지금과는 다른 양상의 부하가 발생할 수 있다. 이때는 다음과 같은 지표들을 주의 깊게 살펴봐야 한다.
- 평소와 다르게 갑자기 TPS가 튀는 시점
- 주기적인 급증 패턴
- TPS는 일정한데 응답 시간이 늘어났을 때의 병목 지점
- TPS는 높지만 에러 리턴 증가
위의 지표들을 바탕으로 병목 발생 여부와 지점을 확인하면 개선 방향을 설정할 수 있다.
2️⃣ B 프로젝트
이번엔 B 프로젝트의 한 엔드포인트를 살펴볼 것이다. DB 접근도 여러 번 일어나고, 외부 API도 4번이나 호출하는 구조이다. 특별한 APM 도구가 없었기 때문에 각 기능 전후로 시간을 측정해 로그로 남겨 계산했다.
| 연산 | 소요 시간 |
| DB 접근 1 | 10.62ms |
| DB 접근 2 | 9.43ms |
| A 서비스 연동 1 | 61.35ms |
| DB 접근 3 | 14.86ms |
| B 서비스 연동 1 | 786.52ms |
| B 서비스 연동 2 | 151.64ms |
| A 서비스 연동 2 | 76.34ms |
| DB 접근 4 | 15.79ms |
| 전체 응답 시간 | 1423.36ms |
이 엔드포인트의 응답시간은 평균 1초를 초과했다. 문제의 핵심은 외부 API 연동 중 B 서비스 연동 1 하나가 전체 응답 시간의 절반 이상을 차지하고 있는 것이다.
구글에 따르면 200ms 이하의 응답 시간이어야 사용자가 즉각적인 반응으로 인식하지만, 대체로 1초까지는 불편감을 느끼지 않는다. 하지만 1초를 넘기는 순간 사용자의 이탈 가능성이 급격히 증가한다고 한다.
According to Google, the average response time should be under 200 milliseconds as it gives the feeling of an instant response. A web response time ranging between 200 milliseconds and 1 second is considered acceptable as users still likely won’t notice the delay. For better user satisfaction, you should take the time to optimize it.
Any response time over 1 second is problematic and needs to be fixed. The higher the response, the higher the chances of users leaving your website or application.
출처 : https://sematext.com/glossary/response-time/
그래서 다음과 같은 개선 방안을 고민했다.
- 가장 시간이 오래 걸리는 외부 API 호출 로직을 분리하기
- 해당 외부 서비스 API 응답 결과를 캐싱하기
- 응답이 필요하지 않은 호출은 비동기 처리하기
1번은 제어할 수 없는 외부 API의 처리 시간을 별도의 로직으로 분리해, 하나의 호출에 대한 응답 시간을 줄이는 효과가 있다. 가장 간단하면서도 사용자의 경험을 개선할 수 있는 방법이다.
2번은 좀 더 다양한 요소를 고려해야 했다. 이 API 호출을 사용자 인증이라고 가정하고 설명해 보겠다.
1. 우선, 실제 호출 내역들을 바탕으로 사용자별 인증 요청 주기를 분석했다. 특정 사용자가 자신의 정보로 인증 요청을 하는 빈도는 하루 평균 1회, 많아야 2~3회 수준이었고, 이마저도 대부분 오전과 오후로 시간대가 분산되는 경향이 있었다.
2. 현재 호출량이 낮은 상태에서 별도 캐시 저장소를 운영하는 것은 오버엔지니어링일 수 있다는 판단이 들었다. 특히 인증의 정확성을 위해 TTL을 짧게 설정할 경우, 캐시 미스가 발생해 오히려 응답 시간이 늘어날 가능성이 있었다.
3번은 이미 순차적으로 호출해야 하는 API를 제외하고 모두 비동기 처리가 된 상태이므로 추가로 개선할 여지가 없었다.
그래서 최종적으로는 1번이 가장 현실적인 선택이라고 판단했다. 그리고 이 과정 덕분에 사수님께 응답 시간 수치를 공유하고 개선점을 논의할 수 있게 되었다.
마무리
사용자에게 좋은 경험을 주기 위해서 성능 측면에서 중요한 처리량과 지연시간에 대해 알아보았다. 비슷해 보이지만 개념적으로 차이가 있는 응답 시간까지 이해할 수 있었다. 실무에서 원하는 모니터링 도구가 갖춰져 있지 않을 수도 있는데, 이때 적절한 도구가 없더라도 로그를 활용해 처리량과 응답 시간을 알아보고 병목 구간을 파악할 수 있다는 점도 중요한 인사이트였다. 아쉽게도 지금까지는 모니터링하는 데 있어서 항상 적절한 도구가 있어야 한다고 생각했기 때문이다.
그리고 비록 현재 트래픽이 많지 않더라도, TPS와 응답 시간을 평소부터 관찰하고 기록하는 습관이 병목 상황에 빠르게 대응하는 데 큰 도움이 될 것이라고 생각하게 되었다.
참고
'노트' 카테고리의 다른 글
| 모니터링 툴 씬의 맛없없 조합: Spring Boot Actuator X Prometheus X Grafana (0) | 2025.03.02 |
|---|---|
| Github Actions (CI) (0) | 2023.02.23 |
| Testcontainers (0) | 2023.02.20 |