
들어가기 전에
인덱스를 이야기하다 보면 클러스터드 인덱스와 넌클러스터드 인덱스를 빼놓을 수가 없다. 참고로 MySQL에서는 넌클러스터드 인덱스와 비슷한 개념인 인덱스를 Secondary Index, 즉 보조인덱스라고 부른다.
이 두 가지가 무엇인지에 대해 먼저 살펴보자.
이 두 개를 비유하면 클러스터형 인덱스는 '영어 사전'과 같은 책이고 보조 인덱스는 책 뒤에 <찾아보기>가 있는 일반 책과 같다.
출처 : 이것이 MySQL이다
이 포스팅에서는 보조 인덱스를 넌클러스터드 인덱스라고 표현하겠다. 이 넌클러스터드 인덱스는 목차가 따로 있어서 찾고 싶은 내용을 목차에 나와 있는 페이지를 통해 실제 내용을 찾을 수 있는 것이다. 반대로 클러스터드 인덱스는 영어 사전처럼 책의 내용 자체가 순서대로 정렬되어 있어서 크게 보면 책 전체가 인덱스 자체인 개념이다. 그래서 행 데이터가 추가되면 인덱스로 지정한 컬럼에 맞춰서 자동으로 정렬된다.
그래서 클러스터드 인덱스는 테이블당 한 개만 생성할 수 있고, 넌클러스터드 인덱스는 테이블당 여러 개를 생성할 수 있다.
아래와 같이 uid를 PK로 가지는 member 테이블을 생성했다고 하자.
CREATE TABLE member (
uid BIGINT NOT NULL PRIMARY KEY,
...
);
그러면 uid 컬럼이 PK가 되면서 클러스터드 인덱스가 생성된다. 이렇게 테이블을 생성할 때 PK로 지정된 컬럼에 클러스터드 인덱스가, Unique로 지정된 컬럼에 넌클러스터드 인덱스가 만들어지는데 이때 만약 PK가 없이 NOT NULL로 설정된 Unique 키가 있다면 이게 클러스터드 인덱스가 된다.
위의 내용을 정리하자면 다음과 같다.
- PRIMARY KEY로 지정한 컬럼은 클러스터드 인덱스가 생성된다.
- UNIQUE NOT NULL로 지정한 컬럼은 클러스터드 인덱스가 생성된다.
- UNIQUE(또는 UNIQUE NULL)로 지정한 컬럼은 넌클러스터드 인덱스가 생성된다.
- PRIMARY KEY와 UNIQUE NOT NULL이 있으면 PRIMARY KEY로 지정한 컬럼에 우선 클러스터드 인덱스가 생성된다.
- PRIMARY KEY로 지정한 컬럼으로 데이터라 오름차순 정렬된다.
Clustered Index
클러스터드 인덱스를 만들어 보자. PK를 지정하지 않고 인덱스를 생성하지 않으면 페이지에 차례대로 데이터가 입력되게 되고 그대로 조회했을 경우에는 정렬과 상관없이 출력된다.
-- 출처 : 이것이 MySQL이다
CREATE TABLE ClusterTbl (
user_id char(8),
name varchar(10)
);
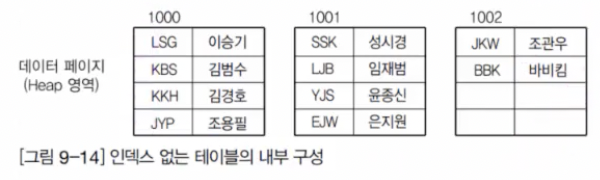
이번에는 user_id를 PK로 지정해서 클러스터 인덱스를 생성해 보겠다.
-- 출처 : 이것이 MySQL이다
ALTER TABLE clusterTbl
ADD CONSTRAINT PK_clusterTbl_userId
PRIMARY KEY (user_id);
다시 데이터를 조회하면 이번에는 user_id 컬럼을 기준으로 정렬이 된 것을 볼 수 있다.

여기서 중요한 것은 리프 노드, 즉 리프 페이지에 있는 데이터 페이지는 인덱스 자체에 포함되어 있다는 사실이다. 그러니까 인덱스 데이터 따로, 저장된 데이터 따로 관리되는 것이 아니라 데이터 자체가 인덱스 안에 포함되어 있어서 앞서 비유한 것과 같이 이 자체가 영어사전 형태가 되는 것이다.
검색
만약 JKW를 조회한다고 했을 때 과정은 다음과 같다.
- J로 시작되는 데이터를 찾기 위해 BBK가 가리키는 1000 페이지로 간다.
- 1000페이지에서 JKW를 찾는다.
페이지를 총 2회 읽게 된다.
삽입
만약 (FNT, 푸니타)라는 정보를 입력한다고 했을 때 F로 시작되는 데이터를 정렬해서 삽입하기 위해서는 1000번 페이지 입력해야 하는데 해당 페이지는 이미 데이터가 가득 차있으므로 페이지 분할이 이루어져야 한다. 이 페이지 분할이라는 작업은 성능에 좋지 않은 영향을 미칠 수 있다.
특징
- 클러스터드 인덱스의 생성 시에는 데이터 페이지 전체가 다시 정렬된다. 그러므로 이미 대용량의 데이터가 입력된 상태라면 업무시간에 클러스터형 인덱스를 생성하는 것은 심각한 시스템 부하를 줄 수 있으므로 신중하게 생각해야 한다.
- 클러스터드 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터다. 그러므로 인덱스 자체에 데이터가 포함되어있다고 볼 수 있다.
- 클러스터드 인덱스는 넌클러스터드 인덱스보다 검색 속도는 더 빠르다. 하지만 데이터의 입력/수정/삭제는 더 느리다.
- 클러스터드 인덱스는 성능이 좋지만 테이블에 한 개만 생성할 수 있다. 그러므로 어느 컬럼에 클러스터드 인덱스를 생성하는지에 따라서 시스템의 성능이 달라질 수 있다.
Non-Clustered Index
이번에는 넌클러스터드 인덱스를 생성하는 쿼리문을 작성해 보자. secondaryTbl에 user_id는 아무 것도 지정하지 않은 상태로 생성되었고 아래에서 UNIQUE 로 지정해준다.
ALTER TABLE secondaryTbl
ADD CONSTRAINT UK_secondaryTbl_userId
UNIQUE (user_id);
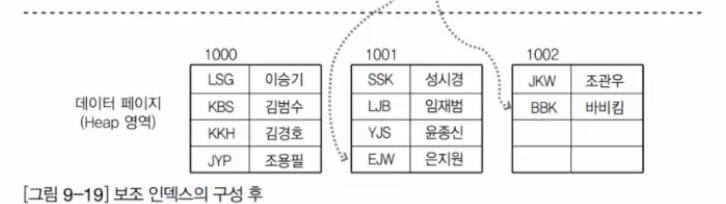
이렇게 넌클러스터드 인덱스가 생성되면 데이터 페이지를 확인하면 알 수 있듯이 데이터의 정렬 자체는 변경되지 않는다. 그리고 인덱스 페이지가 따로 생성되어서 그 안에 리프 페이지에서 데이터를 정렬한 정보를 가지고 있다.
검색
- BBK가 가리키는 100번 페이지로 간다.
- 100페이지에서 JKW가 가리키는 1002번 페이지의 1번째 행으로 간다.
- 데이터 페이지에서 데이터를 읽는다.
삽입
데이터 페이지에서 정렬할 필요가 없으므로 정렬없이 그대로 데이터를 삽입하고 리프 페이지에 정렬해서 저장한다. 위의 예제에서는 리프 페이지에 저장 공간이 남았기 때문에 페이지 분할이 일어나지 않을 것이다.
특징
- 넌클러스터드 인덱스의 생성 시에는 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
- 넌클러스터드 인덱스의 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 주소 값(RID)이다. 클러스터드형보다 검색 속도는 더 느리지만 데이터의 입력/수정/삭제는 덜 느리다.
- 넌클러스터드 인덱스는 여러 개 생성할 수 있다. 하지만, 함부로 남용할 경우에는 오히려 시스템 성능을 떨어뜨리는 결과를 초래할 수 있으므로 꼭 필요한 컬럼에만 생성하는 것이 좋다.
혼재하는 경우
한 테이블에 클러스터드 인덱스와 넌클러스터드 인덱스가 같이 있는 경우를 살펴보자. 아래와 같이 테이블을 생성하게 데이터를 입력했다.
-- 출처 : 이것이 MySQL이다
CREATE TABLE mixedTbl (
user_id char(8) NOT NULL,
name varchar(10) NOT NULL,
addr char(2)
);
PK와 UNIQUE로 클러스터드 인덱스와 넌클러스터드 인덱스를 생성했을 때의 모습을 아래 그림으로 확인할 수 있다.
ALTER TABLE mixedTbl
ADD CONSTRAINT PK_mixedTbl_userId
PRIMARY KEY (user_id);
ALTER TABLE mixedTbl
ADD CONSTRAINT UK_mixedTbl_name
UNIQUE (name);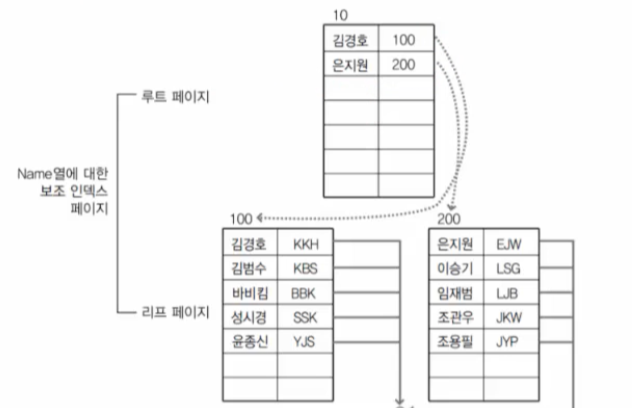
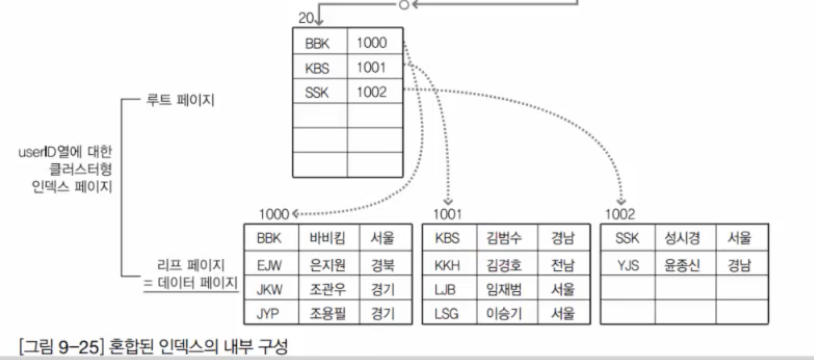
이런 구성을 가질 때 김경호의 주소를 검색한다면 어떻게 될까?
- 보조 인덱스의 루트 페이지에서 김경호를 찾아 100번 페이지로 이동한다.
- 100번 페이지에서 김경호를 가리키는 키인 KKH를 찾는다.
- KKH를 찾기 위해 클러스터드 인덱스 페이지에서 KBS가 가리키는 1001번 페이지로 이동한다.
- 10001번 페이지에서 KKH 김경호의 주소를 찾는다.
확실히 이전보다 더 많은 페이지를 확인해야 하는 것을 알 수 있다. 보조 인덱스의 리프 페이지가 클러스터드 인덱스의 루트 페이지를 찾을 수 있도록 되어 있는데 그냥 바로 클러스터드 인덱스의 데이터 페이지의 주소 값을 가지고 있게 하면 안 되는 걸까? 만약 그렇게 구성이 바뀐다면 아주 큰 문제가 생긴다. 단 한 건의 데이터를 삽입하더라도 클러스터드 인덱스의 데이터 페이지가 페이지 분할을 통해 다시 정렬이 될 것이고 그렇다면 그 정보를 가진 넌클러스터드 인덱스의 리프 페이지까지 변경해야 하기 때문에 시스템의 부하가 발생시킬 수 있게 되는 것이다. 그래서 조금의 손해를 보더라도 시스템의 큰 부하를 주지 않게 내부를 위의 형태로 구성하게 되었다.
참고
[그림 9-25]를 보면 클러스터드 인덱스의 키(KKH, KBS 등)를 넌클러스터드 인덱스가 저장하는 것을 확인할 수 있다. 그러므로 클러스터드 인덱스를 지정할 컬럼의 자릿수가 크다면 넌클러스터드 인덱스에 저장되어야 할 양도 더불어서 많아진다. 그러면 차지하는 공간이 자연히 커질 수밖에 없다. 결국 넌클러스터드 인덱스와 혼합되어 사용하는 경우에는 되도록이면 클러스터드 인덱스로 설정할 컬럼은 적은 자릿수의 컬럼을 선택하는 것이 바람직하다.
출처 : 이것이 MySQL이다
출처
[이것이 MySQL이다] 09. MySQL 인덱스(1)
[이것이 MySQL이다] 09. MySQL 인덱스(2)
[이것이 MySQL이다] 09. MySQL 인덱스(3)
'DB' 카테고리의 다른 글
| [DB] 인덱스(5) - 인덱스로 생성할 컬럼을 선택하는 기준 (0) | 2023.03.15 |
|---|---|
| [DB] 인덱스(4) - Scan의 종류 (0) | 2023.03.14 |
| [DB] 인덱스(2) - B-tree와 B+tree에 대하여 (0) | 2023.03.13 |
| [DB] 인덱스(1) - 인덱스는 왜 사용하는가? (0) | 2023.03.13 |
| [DB] 무조건 정규화가 정답일 수 없는 이유 (1) | 2023.03.08 |



