
들어가기 전에
인덱스로 성능을 개선함에 있어서 가장 중요한 것은 테이블 풀 스캔 횟수를 줄이는 것이다. 그렇다면 도대체 어떤 기준으로 인덱스를 생성할 컬럼을 정해야 할까?
인덱스를 작성하는 필드 집합의 조건은 다음과 같은 두 가지 지표로 판단합니다.
첫 번째는 카디널리티가 높을 것, 즉 값이 평균치에서 많이 흩어져있을수록 좋은 인덱스 후보입니다.
두 번째는 선택률이 낮을 것, 즉 한 번의 선택으로 레코드가 조금만 선택되는 것이 좋은 후보라는 뜻입니다.
출처 : SQL 레벨업
카디널리티는 값의 균형을 나타내는 개념이다. 만약 모든 레코드에 같은 값이 들어가 있다면 카디널리티가 낮은 필드라고 하고 모든 레코드에 다른 값들이 들어가 있으면 높은 필드라고 말할 수 있다.
선택률은 특정 필드값을 지정했을 때 테이블 전체에서 몇 개의 레코드가 선택되는지를 나타내는 개념이다. 만약 'userId = 1'이라는 조회 조건을 걸었을 때 나오는 레코드 수가 적으면 적을수록 좋다는 뜻이다. 만약 100건의 데이터가 있는데 위와 같은 조건으로 하나의 데이터만 조회된다면 선택률은 1%가 되는 것이다. 반대로 위의 조건으로 80건 이상의 레코드 수가 조회된다면 굳이 인덱스로 생성해서 메모리 공간을 사용하고, 정렬하는 데 리소스를 쓰지 않는 게 더 효율적일 수 있다. SQL 레벨업에서는 선택률이 10%보다 높다면 테이블 풀 스캔을 하는 편이 더 빠를 가능성이 커진다고 한다.
종합해 보면 값이 유일해서 조회 조건에 사용했을 때 특정 수준의 레코드 수가 나오도록 하는 컬럼을 선택해야 한다는 것이다. 그렇지 않은 예제들을 통해서 더 알아보자.
선택률
앞서 이야기한 것처럼 조회되는 레코드 수가 절반 이상을 넘어가면서 선택률이 높아져버리면 인덱스 스캔 자체가 비효율적이게 되어버리는 경우가 생길 수 있다. 이 이야기를 할 때 자주 예제로 등장하는 게 성별을 나타내는 'sex' 컬럼인데 이 컬럼에는 두 가지 종류의 데이터만 들어갈 수 있기 때문에 인덱스로서의 의미가 없다. 그러니까 _flg, _status가 붙는 컬럼들도 마찬가지로 인덱스로 생성하기에는 적절하지 않다.
만약 매개변수에 따라 선택률이 변하는 경우에는 어떨까?
-- 출처 : SQL 레벨업
SELECT COUNT(*)
FROM orders
WHERE shop_id = :sid;식당 별로 주문 건수를 조회한다고 했을 때, 대규모 식당은 1000만 건이 선택되고 소규모 식당의 경우 10만 건이 선택된다고 하자. 그러면 선택률은 각각 10%, 0.01%로 다르다. 그러니까 어떤 경우에는 풀 스캔이 더 유리할 수 있고 어떤 경우에는 인덱스 스캔이 유리한 것이다. 옵티마이저가 각각의 경우를 계산하여 적절한 스캔을 선택해주면 좋겠지만 그러지 못하는 경우도 발생할 수 있기 때문에 항상 실행 계획을 확인하고 인덱스를 활용해야 한다.
조회 조건
LIKE 연산자로 조회를 한다고 해보자.
-- 출처 : SQL 레벨업
SELECT order_id
FROM orders
WHERE shop_name LIKE '%대공원%';많은 데이터들 가운데 대공원이 포함된 데이터만 조회할 수 있기 때문에 선택률이 좋아 얼핏 보기에 인덱스를 잘 활용하는 것처럼 보일 수 있다. 하지만 LIKE 연산자가 있는 위치에 집중해보자. 지금처럼 중간에 일치하는 문자를 찾거나 혹은 후방에 일치하는 문자를 찾는 경우에는 인덱스를 활용할 수 없다.
LIKE 연산자를 사용하는 경우에는 인덱스는 전방 일치에만 적용할 수 있다는 것을 기억해야 한다. 즉, 그 외의 경우로 사용될 것 같은 컬럼은 인덱스로 생성하기에 적절하지 않다.
-- 출처 : SQL 레벨업
SELECT order_id
FROM orders
WHERE shop_name LIKE '대공원%';
직접 예제를 만들어서 실행 계획을 살펴보자.
CREATE TABLE Member (
id bigint,
first_name varchar(20)
);
CREATE INDEX firstname_idx ON member (first_name);간단하게 member 테이블을 만들어주고 first_name에 인덱스를 생성했다.
그리고 아래에서 더미데이터 1000건을 만들어서 저장해주고 차례대로 전방일치, 중앙 일치, 후방 일치에 대해 조회해 보겠다.
Mockaroo - Random Data Generator and API Mocking Tool | JSON / CSV / SQL / Excel
Mock your back-end API and start coding your UI today. It's hard to put together a meaningful UI prototype without making real requests to an API. By making real requests, you'll uncover problems with application flow, timing, and API design early, improvi
www.mockaroo.com
전방 일치는 Index Range Scan을 타면서 조회를 하는 것이 확인된다.
SELECT * FROM Member WHERE first_name LIKE 'Ab%';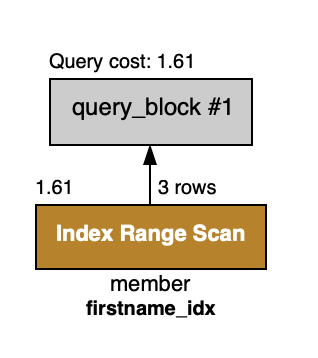
중앙 일치와 후방 일치에 대해서는 같은 결과 값이 나왔는데 아래와 같이 Full Table Scan을 사용해서 조회됐다.
SELECT * FROM Member WHERE first_name LIKE '%Ab%';
SELECT * FROM Member WHERE first_name LIKE '%Ab';
Now imagine that you try to binary search for a value, but you don't know the exact beginning or ending of the value. A binary search is basically not possible and you have to traverse nearly the whole tree to find every possibility.
출처 : https://dba.stackexchange.com/questions/95658/how-does-like-query-work-with-indexed-table
왜 전방 일치만 사용해야 하는지에 대해서는 간단히 B* tree 기반의 이진 탐색을 생각해 보면 된다. 정렬된 순서를 기반으로 탐색을 해야 하는데 그것이 숫자이든, 문자이든 어떤 것으로 시작해야 하는지도 모른다면 어떻게 탐색을 할 수 있을까? 어쩔 수 없이 모든 노드를 탐색해야 하지 않을까? 그래서 결론적으로 풀 스캔이 일어나는 것이다.
LIKE 연산자 외에도 고려해야 하는 경우가 있다.
인덱스 필드로 연산하는 경우
-- 출처 : SQL 레벨업
SELECT * FROM SomeTbl
WHERE col_1 * 1.1 > 100;이럴 때는 우변에만 식을 사용하도록 변경해서 사용할 수 있다.
WHERE col_1 > 100/1.1;IS NULL을 사용하는 경우
-- 출처 : SQL 레벨업
SELECT * FROM SomeTbl
WHERE col_1 IS NULL;
함수를 사용하는 경우
인덱스 내부에 존재하는 값은 함수로 계산된 결과가 아니기 때문에 인덱스가 적용되지 않는다.
-- 출처 : SQL 레벨업
SELECT * FROM SomeTbl
WHERE LENGTH(col_1) = 10;
부정형을 사용하는 경우
부정형(<>, !=, NOT IN)은 인덱스를 사용할 수 없다.
-- 출처 : SQL 레벨업
SELECT * FROM SomeTbl
WHERE col_1 <> 100;
참고
- SQL 레벨업
- SQL BOOSTER
- How does like query work with indexed table
'DB' 카테고리의 다른 글
| [DB] JOIN 알고리즘과 성능에 대하여 (0) | 2023.03.15 |
|---|---|
| [DB] JOIN의 종류 (0) | 2023.03.15 |
| [DB] 인덱스(4) - Scan의 종류 (0) | 2023.03.14 |
| [DB] 인덱스(3) - 클러스터드 인덱스 vs 넌클러스터드 인덱스 (1) | 2023.03.13 |
| [DB] 인덱스(2) - B-tree와 B+tree에 대하여 (0) | 2023.03.13 |



