
들어가기 전에
이 포스팅에서는 데이터를 찾는 방법인 Scan의 종류에 대해서 정리하고자 한다. 아래의 Scan 외에도 여러 방법이 있지만 아래의 종류에 대해서만 언급한다.
- TABLE ACCESS FULL
- INDEX RANGE SCAN
- TABLE ACCESS BY INDEX ROWID
TABLE ACCESS FULL
말 그대로 테이블 전체를 모두 스캔하는 방법이다. 찾으려는 조건에 인덱스가 생성되어있지 않거나 인덱스보다 테이블 전체를 스캔하는 게 효율적이라고 판단될 때 사용된다. member 테이블에서 '김노력'이라는 회원을 찾으려고 할 때 인덱스가 생성되어 있지 않다면 처음에 저장된 행부터 마지막에 저장된 행까지 스캔하면서 데이터를 찾게 되는 것이다. 혹은 아래처럼 WHERE 절에 아무런 조건이 없이 검색될 때도 해당된다.
SELECT * FROM member;
10건도 채 안되는 테이블에서 풀 스캔이 일어나는 것은 그다지 문제되지 않겠지만 만약 천만 건의 데이터를 가진 테이블이 있다면 어떨까? 한 건을 찾기 위해 천만 건을 모두 읽어야 한다면 그거야말로 성능을 반드시 개선시켜야 할 상황이 될 것이다. 하지만 천만 건의 데이터 중 백만 건의 데이터를 찾아야 한다면 풀 스캔이 더 효율적일 수 있다.
요점은 무엇인가 하면, 풀 스캔 자체가 안 좋은 것은 아니라는 것이다. 풀 스캔이 더 효율적이라고 판단되는 경우에 억지로 인덱스를 사용해서 스캔을 한다면 오히려 성능이 떨어질 수 있으므로 맹목적인 인덱스 사용은 피해야 한다.
INDEX RANGE SCAN & TABLE ACCESS BY INDEX ROWID
인덱스로 데이터를 찾는 방법은 굉장히 다양하다.
- INDEX RANGE SCAN
- INDEX SKIP SCAN
- INDEX FULL SCAN
- 등등
이중 가장 기본이 되는 것은 INDEX RANGE SCAN이다.
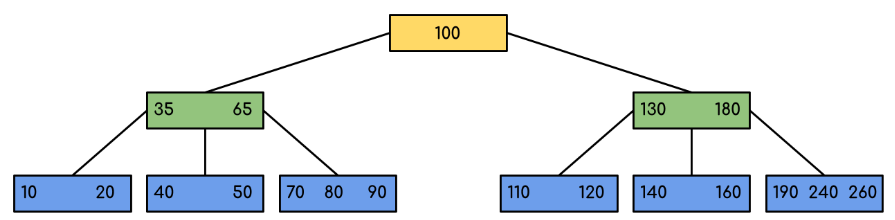
위의 인덱스 구조를 보면 삼각형의 형상이 보인다. 맨 위에는 루트가 있고 제일 아래에는 리프가 있다. 인덱스를 이용해서 데이터를 찾는 과정을 설명하자면 다음과 같다.
- 루트에서 리프로 : 검색 조건에 해당하는 첫 번째 리프 블록을 찾는 과정(굉장히 빠르게 이루어진다)
- 리프 블록 스캔 : 찾아낸 지점부터 리프 블록을 차례대로 읽어 가는 과정
- 테이블 접근 : 리프 블록을 스캔하면서 필요에 따라 테이블에 접근하는 과정
만약 '20230313'이라는 날짜를 검색한다면 '20230313'을 가리키는 리프 블록(=리프 페이지)을 찾아낸 후에 그 안에서 '20230313'보다 큰 데이터를 찾을 때까지 차례대로 읽어나가게 되는데 이 과정이 RANGE SCAN이 되는 것이다.
만약 이 과정에서 테이블에서 필요한 값이 있을 때는 리프 블록의 ROWID 값을 참조해서 테이블의 데이터를 찾아가는 TABLE ACCESS BY INDEX ROWID가 일어난다.
성능 비교
먼저 랜덤 액세스란 용어에 대해 알아보겠다.
IO 작업 한 번에 하나의 블록을 가져오는 접근 방법을 뜻한다. 인덱스의 리프 블록에서 ROWID를 이용해 테이블에 접근할 때 랜덤 액세스가 발생한다. 실행계획에는 'TABLE ACCESS BY INDEX ROWID'로 표시된다. 찾으려는 데이터가 많지 않으면 랜덤 액세스는 나쁜 방법은 아니다. 하지만 찾으려는 데이터가 많으면 랜덤 액세스는 오히려 비효율적이다.
출처 : SQL BOOSTER
위에서 이야기한 것처럼 리프 블록에서 ROWID 값을 참조해서 테이블에 접근할 때 이 랜덤 액세스가 발생한다. 이 개념을 이해하고 아래의 내용을 이어가보도록 해보자.
아래는 INDEX RANGE SCAN을 사용하는 SQL이다.
-- 출처 : SQL BOOSTER
SELECT T1.CUS_ID, COUNT(*) ORD_CNT
FROM T_ORD_BIG T1
WHERE T1.ORD_YMD = '20230313'
GROUP BY T1.CUS_ID,
ORDER BY T1.CUS_ID;검색 조건에 날짜가 있고 그 날짜에 맞는 주문 데이터를 조회하는 쿼리문이다. 이때 ORD_BIG 테이블에 3천만 건의 데이터가 있고 ORD_YMD가 '20230313'인 데이터가 5만 건이 있다고 했을 때 3천만 건에서 5만 건 정도는 INDEX RANGE SCAN이 효율적이라고 판단할 수 있다. 물론 다른 요소들도 고려하여 판단해야 하지만 우선 이 예제에서는 효율적이라고 하겠다.
이번에는 3개월 간의 주문을 조회해 보자.
-- 출처 : SQL BOOSTER
SELECT T1.CUS_ID, SUM(T1.ORD_AMT)
FROM T_ORD_BIG T1
WHERE T1.ORD_YMD BETWEEN '20230113' AND '20230313'
GROUP BY T1.ORD_ST;
이때 TABLE ACCESS BY INDEX ROWID가 실행되는데 이때 실행되는 건수는 직전에 일어난 INDEX RANGE SCAN의 건수와 똑같다. 그림의 A-Rows 부분을 보면 확인할 수 있다. 그러니까 INDEX RANGE SCAN이 일어나는만큼 랜덤 액세스가 발생하는 것이다.
똑같은 상황에서 FULL SCAN 방식으로 처리한다면 어떻게 될까?

랜덤 액세스가 추가로 발생하지 않으니 훨씬 검색 속도가 빨라졌다. 총 실행 시간도 30초 대에서 4초 대로 단축되는 것을 확인할 수 있다.
정리
- 적은 양의 데이터를 읽는다면 INDEX RANGE SCAN이 유리하다.
- 많은 양의 데이터를 읽어야 한다면 FULL SCANd이 유리할 수 있다.
- FULL SCAN은 데이터가 쌓일수록 성능이 점차 나빠진다.
세 번째 이야기는 무엇이냐 하면, 앞서 TABLE ACCESS FULL SCAN에서 이야기한 천만 건의 데이터를 예로 들 수가 있겠다. 천만 건의 데이터에서 백만 건의 데이터를 찾는다고 했을 때는 인덱스보다 FULL SCAN이 유리할 수 있다. 그렇지만 만약 계속해서 데이터는 쌓이는데 찾아야 하는 데이터는 백만 건이라면 그때는 FULL SCAN이 유리하다고 말할 수 없을 것이다.
참고
SQL BOOSTER
'DB' 카테고리의 다른 글
| [DB] JOIN의 종류 (1) | 2023.03.15 |
|---|---|
| [DB] 인덱스(5) - 인덱스로 생성할 컬럼을 선택하는 기준 (0) | 2023.03.15 |
| [DB] 인덱스(3) - 클러스터드 인덱스 vs 넌클러스터드 인덱스 (1) | 2023.03.13 |
| [DB] 인덱스(2) - B-tree와 B+tree에 대하여 (0) | 2023.03.13 |
| [DB] 인덱스(1) - 인덱스는 왜 사용하는가? (0) | 2023.03.13 |



