
들어가기 전에
앞서 정규화에 대해 알아봤는데 정규화로 재정의된 테이블들의 정보를 모두 가져오기 위해서는 JOIN을 활용해야 한다. 하지만 JOIN을 사용하기 때문에 성능이 안 좋아진다는 단점이 있어 반정규화(=역정규화)를 수행하기도 한다는 이야기를 했었다. 그렇다면 이 JOIN은 항상 좋지 않은 결과만을 가져오는 것일까? SQL BOOSTER의 글을 인용해 보겠다.
조인을 사용하면 안 된다고 주장하는 사람도 있다. 아래와 같은 이유다.
'조인하면 결과가 무조건 맞지 않아! 다 틀려.'
조인을 정확히 사용하면, 설계가 잘못되지 않는 이상 부정확한 결과가 나올 일은 없다. 조인을 다시 익힐 필요가 있다.
'조인하면 성능이 안 좋아. 너무 느려.'
SQL 성능에는 다양한 원인이 있다. 조인 때문에 성능이 나쁘다고 단정하기는 어렵다.
조인을 안 쓰기 시작하면 데이터가 중복되고 늘어난다. 이로 인해 데이터베이스 전체 성능은 더 나빠질 수 있다.
'정규화'를 주장하는 것이 아니다. 성능과 개발 편의를 위해, 적절한 '반정규화'는 필요하다.
다만 위와 같은 이유로 무작정 '조인'을 피하려고 해서는 안 된다는 얘기다.
출처 : SQL BOOSTER
무조건 JOIN을 사용하는 게, 무조건 정규화를 사용하는 게 정답이 될 수는 없다. JOIN에 대해 정확히 파악하고 정규화를 했을 때와 반정규화를 했을 때의 성능을 비교해 가면서 선택하는 것이 정답일 것이다.
그러기 위해서는 JOIN을 정확히 알아야 하겠다. 이번 포스팅에서는 JOIN의 종류에 대해 정리해 보려고 한다.
- INNER JOIN
- OUTER JOIN
- CARTESIAN JOIN
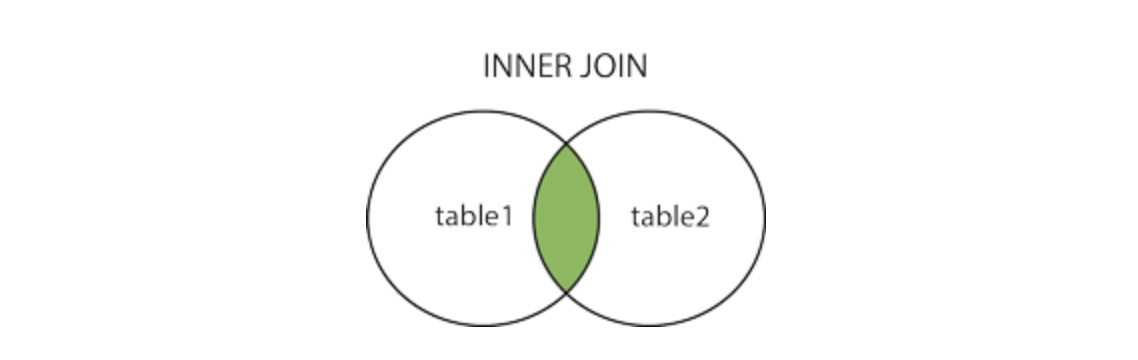
INNER JOIN
INNER JOIN은 가장 많이 사용되는 형태로 조인 조건을 만족하는 데이터만 결합해서 결과로 내보낸다.
사원의 부서 이름을 알기 위해 Employee 테이블과 Departments 테이블을 결합하고 JOIN 조건을 설정했다.
-- 출처 : SQL 레벨업
SELECT E.emp_id, E.emp_name, E.dept_id, D.dept_name
FROM Employees E INNER JOIN Departments D
ON E.dept_id = D.dept_id;이때 실행된 결과는 두 개의 테이블의 모든 데이터 중 JOIN 조건이 일치하는 데이터를 필터링해서 가져온다.
좀 더 자세한 과정을 살펴보기 위해 고객(M_CUS) 테이블과 주문(T_ORD) 테이블을 INNER JOIN하는 예제를 가져왔다.
-- 출처 : SQL BOOSTER
SELECT T1.CUS_ID, T1.CUS_GD, T1.ORD_SEQ, T2.CUS_ID, T2.ORD_DT
FROM M_CUS T1, T_ORD T2
WHERE T1.CUS_ID = T2.CUS_ID
AND T.CUS_GC = 'A'
AND T2.ORD_DT >= TO_DATE('20170101', 'YYYYMMDD')
AND T2.ORD_DT < TO_DATE('20170201', 'YYYYMMDD');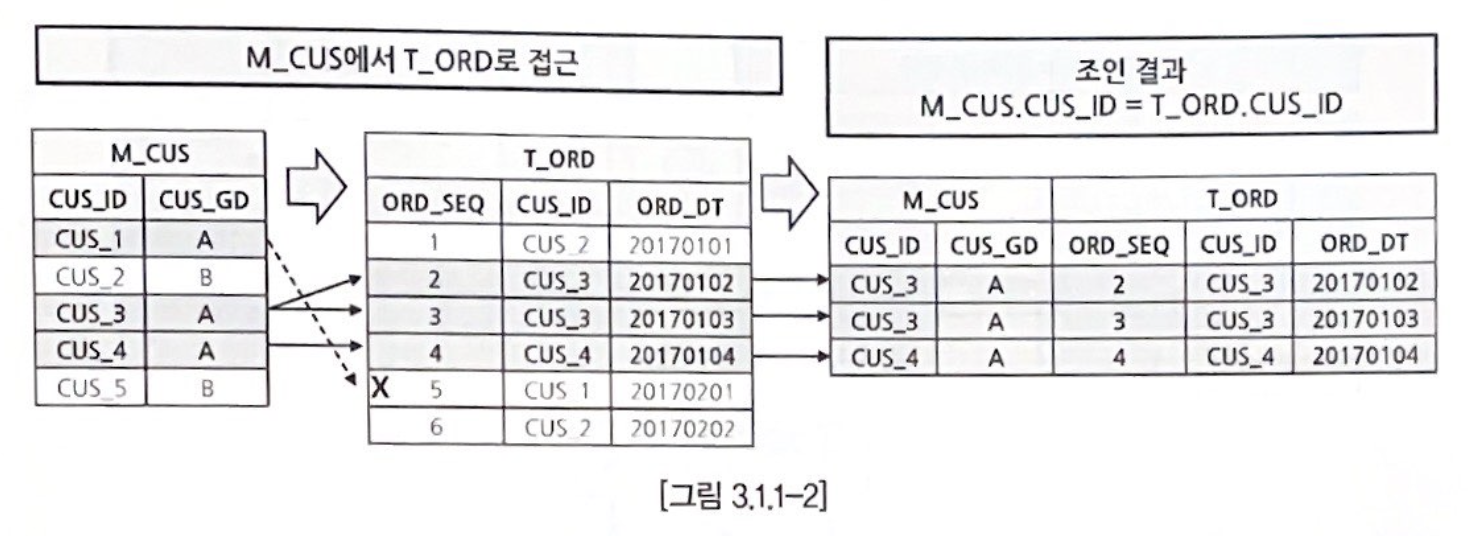
상세 과정
1. M_CUS에서 CUS_GD가 A인 데이터만 찾아낸다. (필터 조건 처리)
2. M_CUS에서 첫 번째 로우인 CUS_1과 같은 CUS_ID가 T_ORDd에 있는지 검색한다.
: T_ORD에 CUS_1이 존재하지만 ORD_DT가 2017년 2월이므로 조인에 실패한다.
(T_ORD의 필터 조건이 2017년 1월의 주문만 처리하기 때문이다.)
3. M_CUS의 세 번째 로우인 CUS_1과 같은 CUS_ID가 T_ORDd에 있는지 검색한다.
: T_ORD에는 CUS_3이 두 건 존재한다. ORD_DT도 2017년 1월이므로 조인에 성공한다.
(M_CUS의 CUS_3 한 건은 T_ORD의 두 건과 조인이 이루어진다.)
4. M_CUS의 네 번째 로우인 CUS_4와 같은 CUS_ID가 T_ORD에 있는지 검색한다.
: T_ORD에 CUS_4는 한 건 존재한다. ORD_DT도 2017년 1월이므로 조인에 성공한다.
그러니까 위의 쿼리문에는 필터 조건이 있기 때문에 필터 조건을 만족하는 데이터를 먼저 추려내고, 그 후에 JOIN 조건을 만족하는 데이터를 찾아서 내보내는 것이다. 여기서 M_CUS에서 CUS_3은 한 건이지만 T_ORD의 두 건의 데이터와 JOIN되면서 두 건의 데이터가 되는 것을 기억해두자. 1:1로 JOIN이 이루어지는지, 1:M으로 이루어지는지에 따라 결과의 개수가 다르다.
만약 이 과정의 처리 순서가 달라진다면 어떻게 될까? 성능에는 차이가 있을 수 있어도 JOIN 결과에는 차이가 없다. 그리고 JOIN 조건에서 보통 '=' 등호를 사용해서 같은 값끼리만 JOIN할 수 있다고 생각할 수 있지만 같지 않은 값에 대해서도 결합할 수 있기 때문에 상황에 맞춰서 사용하면 된다. '=', '!=', '범위(LIKE, >, <)' 조건을 사용할 수 있다.
특징
- JOIN 조건을 만족하는 데이터만 결합되어 결과에 나올 수 있다. (이때, 조건은 '같다(=)' 뿐만 아니라, 다른 조건식도 사용할 수 있다.)
- 한 건과 M(Many) 건이 JOIN되면 M건의 결과가 나온다.
- 여러 테이블을 조인할 때는
- 한 순간에는 두 개의 테이블에 대해서만 JOIN이 발생한다.
- 세 개의 테이블인 경우 JOIN이 이루어진 두 개의 테이블은 새로운 하나의 데이터 집합으로 또 다른 테이블과의 JOIN이 이루어진다.
- 테이블 간의 관계를 이해하고 JOIN을 작성하자.
OUTER JOIN
OUTER JOIN은 JOIN 조건에 만족하지 않은 결과도 내보내는 형태로 세 가지 종류가 있다.
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
OUTER JOIN은 기준이 되는 테이블과 참조하는 테이블을 구분해서 사용하는데 기준이 되는 테이블은 필터 조건만 만족하면 조인 조건을 만족하지 않아도 모두 결과에 포함된다. 참조 테이블에 (+)를 붙이는 것으로 표시할 수 있다.
아래와 같은 쿼리문을 실행했을 때의 결과를 보며 위의 내용을 이해해보자.
-- 출처 : SQL BOOSTER
SELECT T1.CUS_ID, T1.CUS_NM, T2.CUS_ID, T2.ITM_ID, T2.EVL_LST_NO
FROM M_CUS T1, T_ITM_EVL T2
WHERE T.CUS_ID = 'CUS_0002'
AND T1.CUS_ID = T2.CUS_ID(+);| M_CUS | T_ITEM_EVL | |||
| CUS_ID | CUS_NM | CUS_ID | ITM_ID | EVL_LST_NO |
| CUS_0002 | NAME_0002 | NULL | NULL | NULL |
- JOIN 조건에 (+) 표시가 있기 때문에 OUTER JOIN을 사용하고 있고 T_ITM_EVL 테이블이 참조 테이블인 것을 알 수 있다.
- (+) 표시가 없는 M_CUS 테이블은 자동으로 기준 테이블이 되고 JOIN에 성공 못해도 결과값이 나오며 해당하지 않는 결과들은 NULL로 표시된다.
종류
아래의 LEFT OUTER JOIN, RIGHT OUTER JOIN은 결국에 기준 테이블을 어디에 두느냐의 차이이고 실질적으로 같은 기능을 한다.
SELECT T1.col1, T1.col2, T2.col3
FROM Tbl1 T1 LEFT OUTER JOIN Tbl2 T2
ON T1.col2 = T2.col2;
SELECT T1.col1, T2.col2, T2.col3
FROM Tbl1 T1 RIGHT OUTER JOIN Tbl2 T2
ON T1.col2 = T2.col2;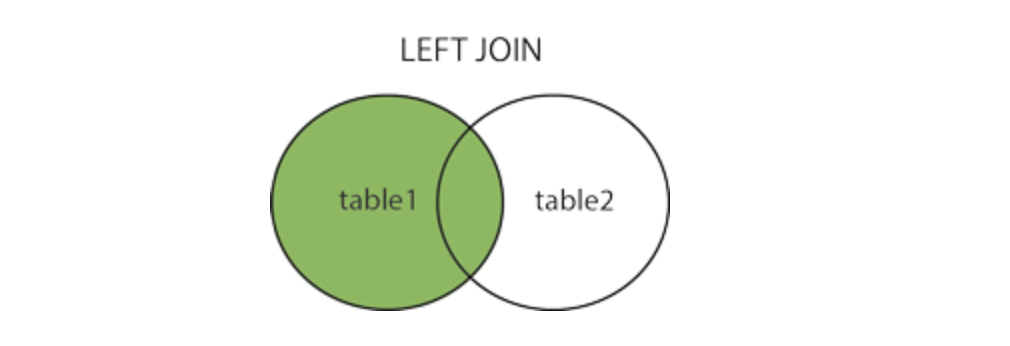
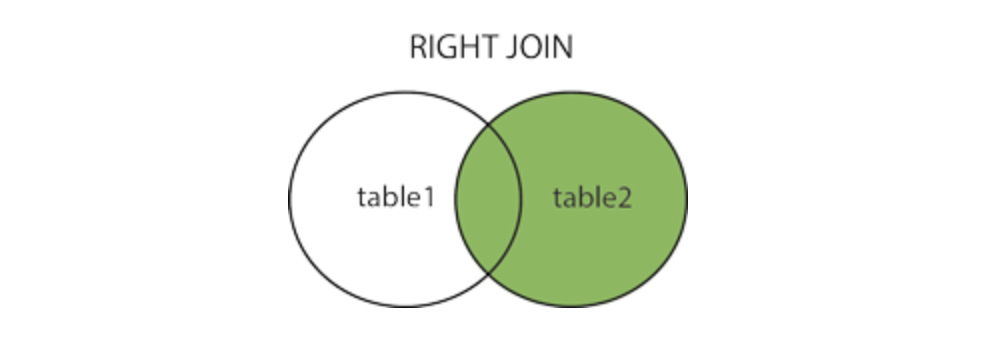
FULL OUTER JOIN은 JOIN 조건에 만족하지 않는 결과들이 모두 결합되는 것인데 아래의 예제를 보면 쉽게 이해가 될 것이다.
-- 출처 : https://www.w3schools.com/sql/sql_join_full.asp
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName;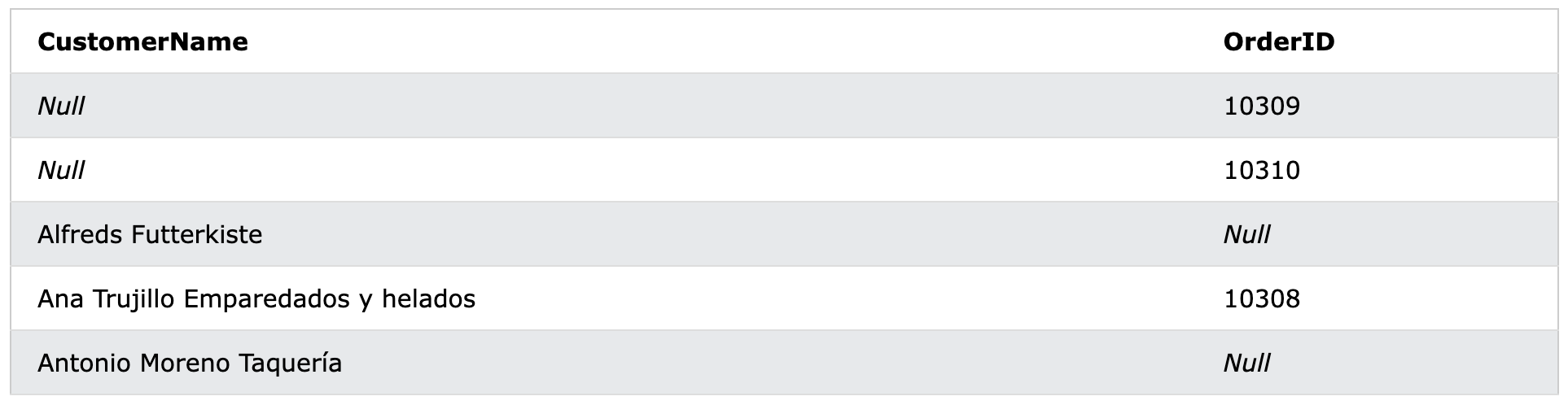
CustomerID가 일치하는 것은 OrderID가 10308인 4번째 행밖에 없었기 때문에 나머지 일치하지 않는 각각의 항목들은 Null로 표현됐다.
특징
- 기준 테이블은 JOIN 조건에 (+)가 없는 쪽고 반대로 참조 테이블은 (+)가 표시된 쪽이다.
- 기준 테이블의 데이터는 필터 조건을 만족하는 경우 JOIN 성공 여부와 상관없이 모두 나온다.
- 이 때, 참조 테이블의 결과는 NULL 값으로 채워진다.
- 참조 테이블의 필터 조건에 (+)를 표시하면 OUTER JOIN 전에 필터가 된다.
- 표시하지 않으면 OUTER JOIN 후 필터가 된다.
- 일반적으로는 필터 조건에 (+)를 표시한다.
- 참조 테이블이 다른 테이블과 JOIN될 때는 기준 테이블로서 OUTER JOIN 해야 한다.
CARTESIAN JOIN
JOIN 조건 없이 두 테이블을 결합한 결과를 내보낸다. A 테이블에 2건, B 테이블에 4건의 데이터가 있다면 결과 건수는 'A 테이블의 건수 * B 테이블의 건수 = 2 *4'로 8건이 된다.

CARTESIAN JOIN은 데이터를 분석할 때 사용하거나 혹은 대량의 테스트 데이터를 만들기 위해 일회성으로 사용되고, 실무에서는 거의 사용하지 않는다. 다음은 SQL 레벨업에서 이야기하는 이 결합 방식이 실무에서 사용되지 않는 이유이다.
1. 이러한 결과가 필요한 경우가 없다.
2. 비용이 매우 많이 드는 연산이다.
참고
- SQL 레벨업
- SQL BOOSTER
- https://www.w3schools.com/sql/
'DB' 카테고리의 다른 글
| [MyBatis] MyBatis 설정과 log4jdbc-log4j2 적용기 (0) | 2023.03.31 |
|---|---|
| [DB] JOIN 알고리즘과 성능에 대하여 (0) | 2023.03.15 |
| [DB] 인덱스(5) - 인덱스로 생성할 컬럼을 선택하는 기준 (0) | 2023.03.15 |
| [DB] 인덱스(4) - Scan의 종류 (0) | 2023.03.14 |
| [DB] 인덱스(3) - 클러스터드 인덱스 vs 넌클러스터드 인덱스 (1) | 2023.03.13 |



