
들어가기 전에
우리는 결합의 결과를 도출해 내기 위해 간단히 JOIN 연산을 사용했다. 그렇다면 DBMS 내부에서는 어떻게 이 JOIN 연산을 처리하게 되는 것일까? JOIN 연산을 수행할 때 내부적으로 선택되는 알고리즘에 대해 알아보자.
- Nested Loops Join
- Hash Join
- Sort Merge Join
위의 세 가지 알고리즘은 옵티마이저가 선택 가능한 알고리즘들인데 모든 DBMS가 지원하는 것은 아니다. MySQL의 경우에는 8.0.18 버전 이전에는 Nested Loops와 이를 변형한 알고리즘들만을 지원했는데 8.0.18 버전 이후부터는 Hash Join을 지원하기 시작했다.
Prior to MySQL 8.0.18, this algorithm was applied for equi-joins when no indexes could be used; in MySQL 8.0.18 and later, the hash join optimization is employed in such cases. Starting with MySQL 8.0.20, the block nested loop is no longer used by MySQL, and a hash join is employed for in all cases where the block nested loop was used previously. See Section 8.2.1.4, “Hash Join Optimization”
출처 : https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html#block-nested-loop-join-algorithm
Nested Loops Join
간략하게 NL이라고도 불리는 이 알고리즘은 이름 그대로 중첩 반복을 사용하는 알고리즘이다. 우리가 아는 그 중첩 반복문을 JOIN에 사용하는 형식이다.
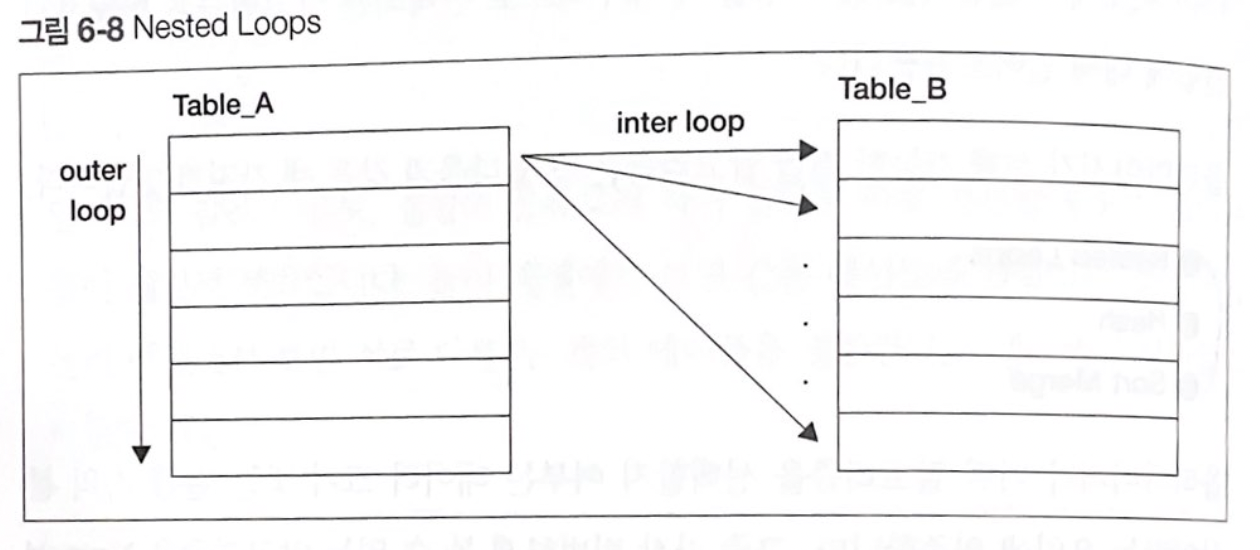
위의 그림의 세부 처리 과정은 다음과 같다.
1. Table A에서 레코드를 하나씩 반복해가며 스캔한다. 이 테이블을 구동 테이블(driving table) 또는 외부 테이블(outer table)이라고 부른다. Table B는 내부 테이블(inner table)이라고 부른다.
2. 구동 테이블(Table A)는 레코드 하나마다 내부 테이블(Table B)의 레코드를 하나씩 스캔해서 결합 조건에 맞으면 리턴한다.
3. 이러한 작동을 구동 테이블의 모든 레코드에 반복한다.
특징
- Table A, TAble B의 결합 대상 레코드를 R(A), R(B)라고 하면 접근되는 레코드 수는 R(A) X R(B)가 된다. Nested Loops의 실행 시간은 이러한 레코드 수에 비례한다. (EXISTS와 같은 조건을 사용했을 때는 레코드 수가 감소할 수 있다.)
- 한 번의 단계에서 처리하는 레코드 수가 적으므로 Hash 또는 Sort Merge에 비해 메모리 소비가 적다.
- 모든 DBMS에서 지원한다.
고려 사항
처음으로 고려해야 할 것은 어떤 테이블을 구동 테이블로 사용할지 선택하는 것이다. 구동 테이블은 레코드 수가 작은 테이블을 선택해야 한다. 아무래도 반복해서 스캔해야 하는 레코드 수가 작아야 한다는 건 너무나도 당연한 것처럼 느껴질 것이다.
그렇다면 내부 테이블은 어떨까? 그 다음으로 고려해야 할 것은 내부 테이블의 반복을 얼마냐 생략할 수 있느냐이다. 만약 내부 테이블에 인덱스가 생성되어 있는 경우에는 내부 테이블을 모두 반복하지 않아도 되기 때문에 그렇지 않을 때보다는 성능을 개선할 수 있다.
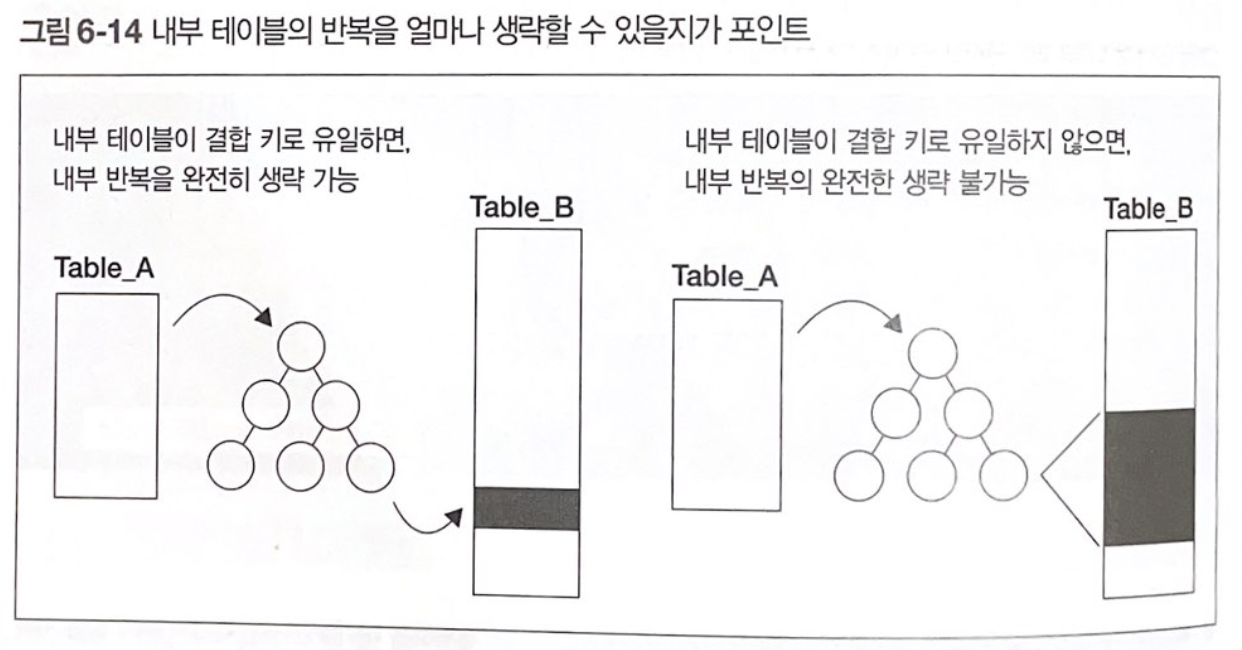
그러니까 '구동 테이블이 작은 Nested Loops' + 'JOIN에 사용할 컬럼에 인덱스가 생성되어 있는 내부 테이블' 조합이 기본이 되어야 되는 것이다.
하지만 모든 레코드가 이런 관계로 성립이 되지는 않을 것이다. 만약 내부 테이블의 선택률이 높으면 아무리 구동 테이블이 작더라도 성능이 악화될 수밖에 없다. 이럴 때는 오히려 레코드 수가 많은 테이블을 구동 테이블로 선택하거나 Hash Join으로 알고리즘을 변경하는 것이 좋다.
Hash Join
Hash Join은 해시 함수를 이용한 알고리즘이다. 우선 작은 테이블을 스캔하고, JOIN으로 사용할 컬럼 값에 해시 함수를 적용해서 해시 값으로 변환한다. 그리고 다른 테이블을 스캔하고, JOIN 컬럼이 해시 값에 존재하는지 확인한다.

작은 테이블에서 해시 테이블을 만드는 이유는 해시 테이블이 DBMS의 워킹 메모리에서 저장되기 때문에 조금이라도 작게 만들어서 메모리 사용량을 줄이기 위해서이다.
특징
- 결합 테이블로부터 해시 테이블을 만들어서 활용하므로, Nested Loops에 비해 메모리를 크게 소모한다.
- 메모리가 부족하면 저장소를 사용하므로 지연이 발생한다.
- 출력되는 해시 값은 입력 값의 순서를 알지 못하므로, 등치 결합에만 사용할 수 있다.
Hash Join이 유용한 경우
- Nested Loops에서 적절한 구동 테이블(상대적으로 충분히 작은 테이블)이 존재하지 않는 경우
- 구동 테이블로 사용할만한 작은 테이블은 있지만, 내부 테이블에서 히트되는 레코드 수가 너무 많은 경우
- Nested Loops의 내부 테이블에 인덱스가 존재하지 않는(또는 여러 가지 사정에 의해 인덱스를 추가할 수 없는) 경우
하지만 Hash Join에서도 고려해야 할 사항들이 있다. 특징에 나와있는 것처럼 해싱 할 때 워킹 메모리를 따로 사용하는데 동시 실행성이 높은 OLTP를 처리할 경우에 메모리가 부족해져서 저장소를 사용할 가능성이 있다. 그렇게 되면 아무래도 I/O 접근 시간으로 인해서 지연이 발생할 수 있기 때문에 OLTP 처리에서는 Hash Join을 선택하면 안 되고 동시 처리가 적은 야간 배치나 데이터 수집을 할 때 사용하는 것이 좋다. 그리고 결국에는 양쪽 테이블의 레코드를 모두 읽어야 하기 때문에 테이블 규모가 크다면 Full Scan에 걸리는 시간도 고려해야 한다.
Sort Merge Join
간단하게 Merge 또는 Merge Join으로도 불리는 이 알고리즘은 각각의 테이블을 정렬한 후에 정렬된 데이터를 차례대로 읽어가면서 일치하는 JOIN 조건을 찾을 때 결합한다.
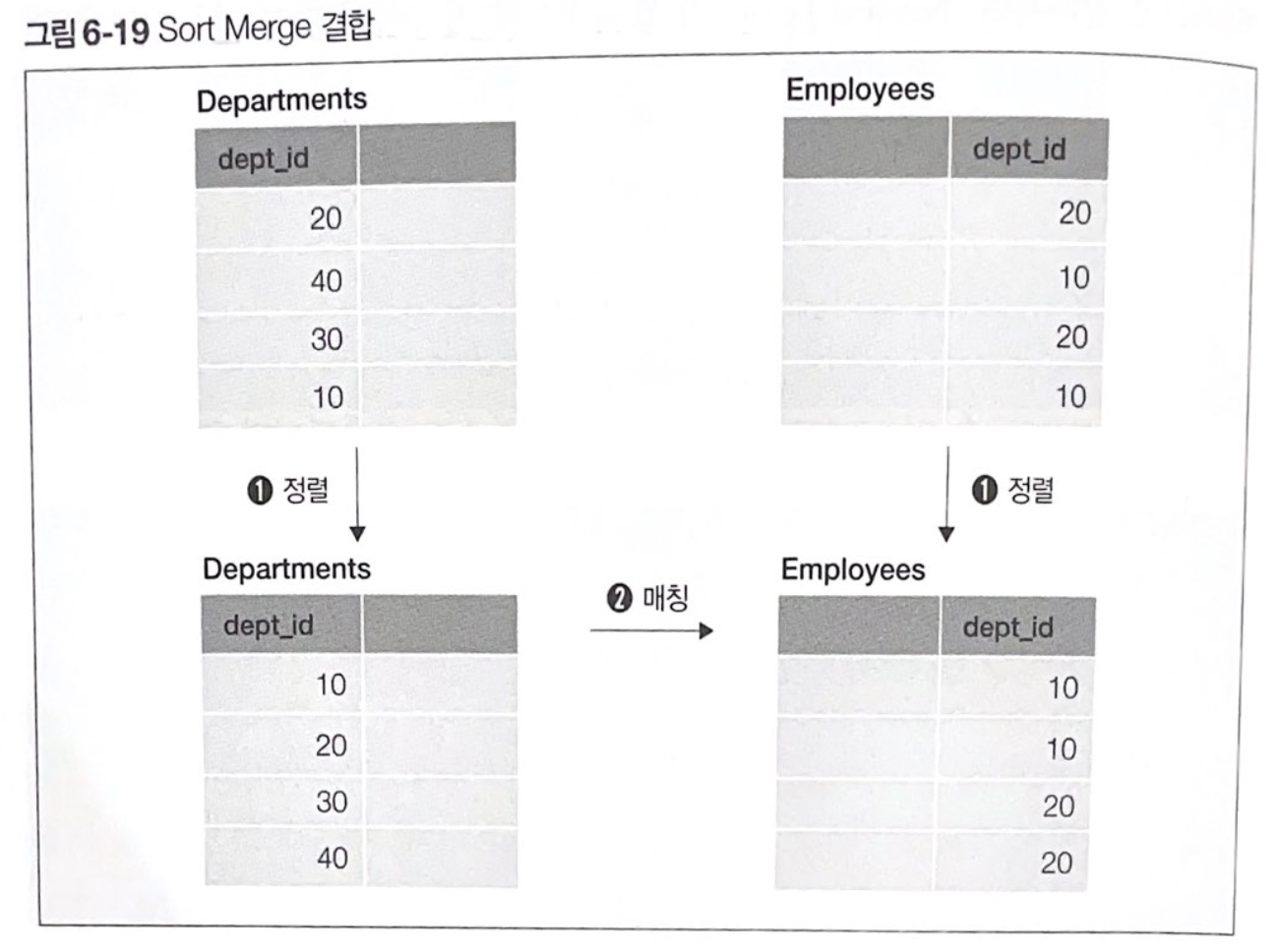
특징
- 대상 테이블을 모두 정렬해야 하므로 Nested Loops보다 많은 메모리를 소비한다. Hash와 비교하면 규모에 따라 다르지만, Hash는 한쪽 테이블에 대해서만 해시 테이블을 만들기 때문에 Hash보다 많은 메모리를 사용하기도 한다. 메모리 부족으로 I/O 비용이 늘어나고 지연이 발생할 위험이 있다.
- Hash와 다르게 동치 결합뿐만 아니라 부등호(<, >, <=, >=)를 사용한 결합에도 사용할 수 있다. 하지만 부정 조건(<>)에서는 사용할 수 없다.
- 원리적으로는 테이블이 이미 JOIN 컬럼으로 정렬되어 있다면 정렬을 생략할 수 있다.
- 테이블을 정렬하므로 한쪽 테이블을 모두 스캔한 시점에 결합을 완료할 수 있다.
이 알고리즘은 정렬 시간을 얼마나 줄일 수 있느냐가 성능 향상의 주요 포인트이다. 테이블 정렬에 많은 시간과 리소스가 요구될 수 있기 때문이다. 그래서 테이블 정렬을 생략할 수 있는 경우가 아니라면 우선적으로는 NL과 Hash를 고려해야 한다.
상황에 따른 최적의 알고리즘
| 이름 | 장점 | 단점 |
| Nested Loops | - '작은 구동 테이블' + '내부 테이블의 인덱스'라는 조건이 있다면 굉장히 빠르다. - 메모리 또는 디스크 소비가 적으므로 OLTP에 적합 - 비등가 결합에서도 사용 가능 |
- 대규모 테이블들의 결합에는 부적합 - 내부 테이블의 인덱스가 사용되지 않거나, 내부 테이블의 선택률이 높으면 느리다. |
| Hash | 대규모 테이블들을 결합할 때 적합 | - 메모리 소비량이 큰 OLTP에는 부적합 - 메모리 부족이 일어나면 저장소 사용 - 등가 결합에서만 사용 가능 |
| Sort Merge | - 대규모 테이블들을 결합할 때 적합 - 비등가 결합에서도 사용 가능 |
- 메모리 소비량이 큰 OLTP에는 부적합 - 메모리 부족이 일어나면 저장소 사용 - 데이터가 정렬되어 있지 않다면 비효율적 |
사용할 수 있는 메모리의 양 또는 JOIN으로 사용되는 컬럼의 카디널리티 등 세세한 조건에 따라 최적의 방법은 바뀔 수 있다. 테이블의 규모만으로 정리하자면 다음과 같을 수 있다.
- 소규모 - 소규모
- 결합 대상 테이블이 작은 경우에는 어떤 알고리즘을 사용해도 성능 차이가 크지 않다.
- 소규모 - 대규모
- 소규모 테이블을 구동 테이블로 하는 NL을 사용한다. 대규모 테이블의 결합 키에는 인덱스가 만들어져야 한다. 하지만 내부 테이블의 결합 대상 레코드가 너무 많다면 구동 테이블과 내부 테이블을 바꾸거나 Hash 사용을 고려한다.
- 대규모 - 대규모
- 우선적으로 Hash를 고려하지만 이미 데이터가 정렬되어 있는 상태라면 Sort Merge를 사용할 수도 있다.
힌트를 사용하지 않는 한 어떤 알고리즘을 선택할지는 옵티마이저가 결정한다. 그러니 옵티마이저가 더 나은 선택을 할 수 있게 하기 위해서는 인덱스를 잘 구성해줘야 한다. SQL BOOSTER에서는 이렇게 조언한다.
하나의 SQL을 NL, 머지, 해시 조인으로 다양하게 시도해 보고 실행 계획으로 성능을 확인하는 연습이 필요하다.
조인 방법뿐 아니라, 조인 순서와 인덱스도 다양하게 변경해 보도록 한다.
꾸준히 연습하다 보면 테이블과 SQL만 봐도 어떤 조인 방식이 좋은지 저절로 알 수 있다.
위의 테이블 규모도 항상 정답일 수 없기 때문에 DB를 다룰 때는 직접 실행 계획을 살펴보고 결정해야하겠다.
참고
- SQL BOOSTER
- SQL 레벨업
'DB' 카테고리의 다른 글
| [MySQL] SQL state [HY000]; error code [1366]; Incorrect string value (0) | 2023.03.31 |
|---|---|
| [MyBatis] MyBatis 설정과 log4jdbc-log4j2 적용기 (0) | 2023.03.31 |
| [DB] JOIN의 종류 (0) | 2023.03.15 |
| [DB] 인덱스(5) - 인덱스로 생성할 컬럼을 선택하는 기준 (0) | 2023.03.15 |
| [DB] 인덱스(4) - Scan의 종류 (0) | 2023.03.14 |